Classifiers
Classifiers are a machine learning technique used to identify the label of a data point based on previously identified labels. We create classifiers using supervised learning, meaning we label all inputs for the machine to learn from. A classifier is created by defining training data (a set of input data points along with their correct labels). Once trained, there are many ways a classifier can predict data.
We collected data samples for our training data set and created a variety of classifiers by feeding the data set into different models. By testing a variety of classifiers and observing the performance of each, we identified which were best to use on our type of data.
We collected data samples for our training data set and created a variety of classifiers by feeding the data set into different models. By testing a variety of classifiers and observing the performance of each, we identified which were best to use on our type of data.
|
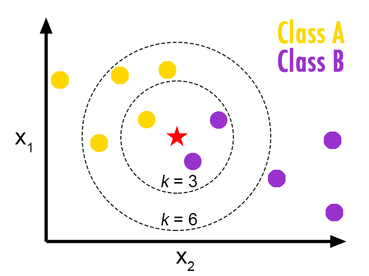
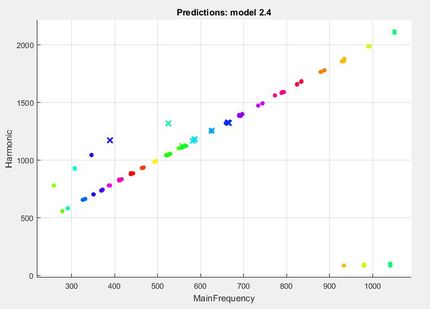
K-Nearest Neighbor (KNN) Predicts the label of a data point based on the K nearest data points; a higher K value averages over larger range of points in order to make an identifying prediction Results of the KNN Classifier on our Training Data: |
http://bdewilde.github.io/blog/blogger/2012/10/26/classification-of-hand-written-digits-3/
|
|
|
|
This scatter plot displays correctly identified points as dots and incorrectly identified points with an 'x'
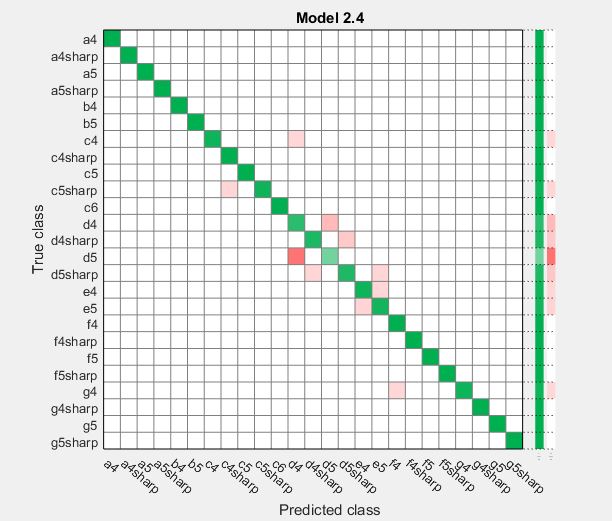
- Had the highest accuracy of 94.8% |
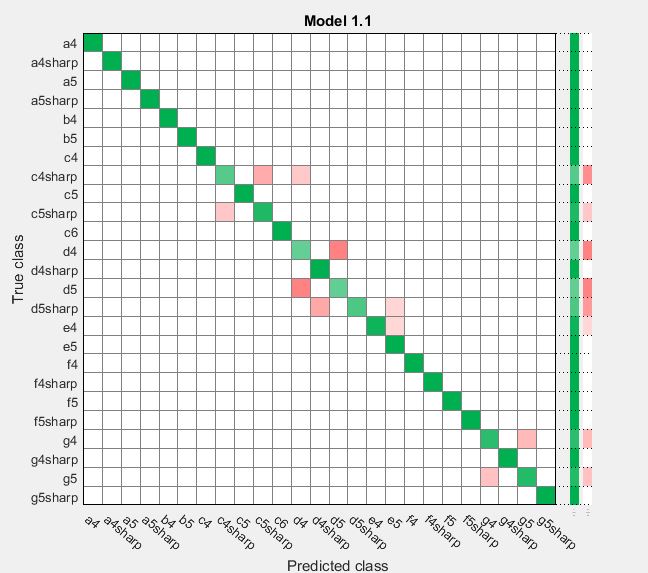
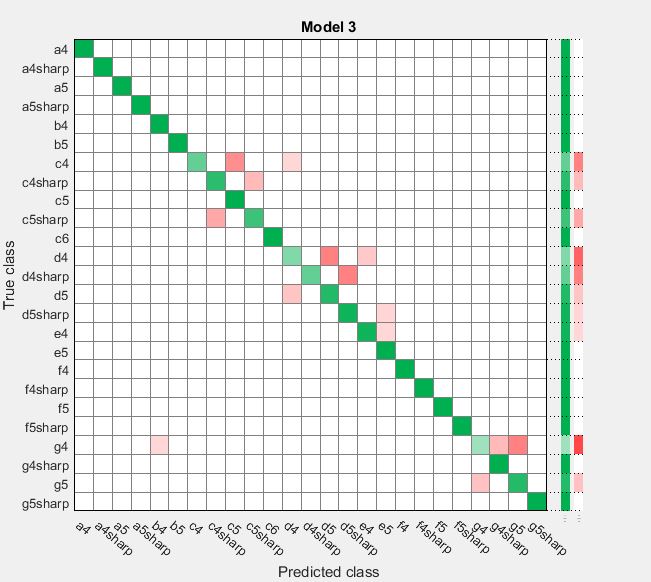
This confusion matrix plots predicted label on the x axis and actual label on the y axis. If they are the same, the intersecting box is green. If then are different, the intersecting box is red.
|
|
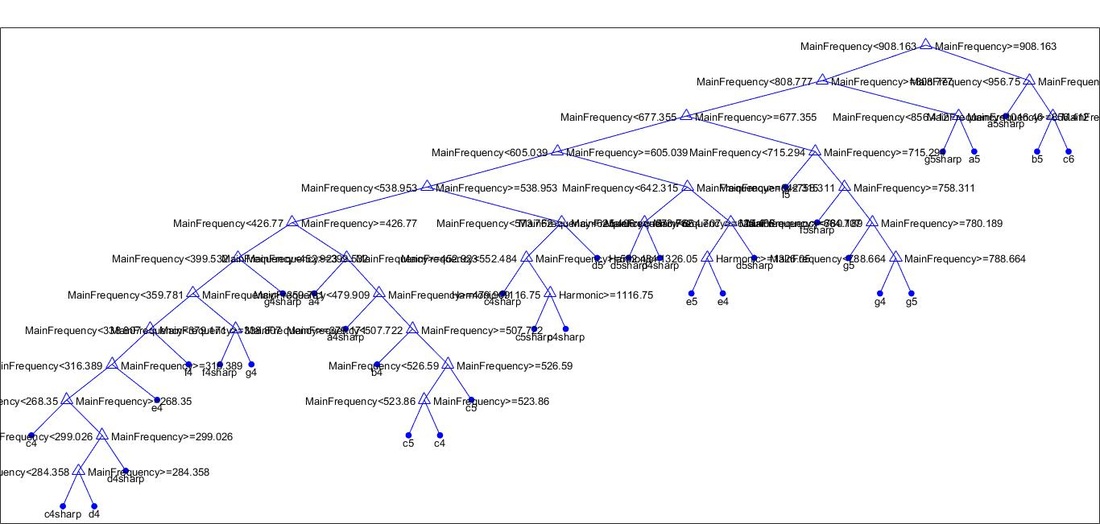
Complex Tree
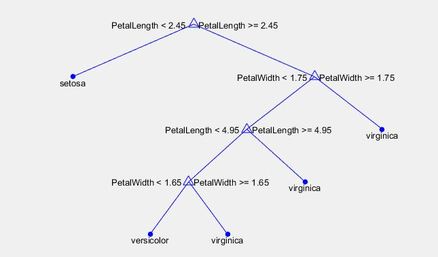
Predicts the label of a data point based on key features in the data; makes decisions of classification at each node of the tree Results of the Complex Tree Classifier on our Training Data: |
https://www.mathworks.com/help/stats/choose-a-classifier.html
|
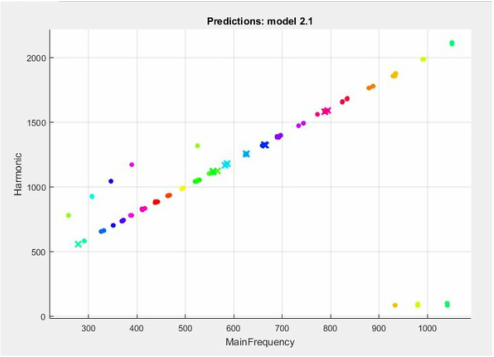
- Accuracy of 91.2% slightly lower than KNN model, but predicts more correct notes when tested on prediction data This is our complex tree classifier created from training data: |
|
|
Support Vector Machine (SVM)
Predicts the label of a data point based on which general group of data it appears to falls in; creates sections in the data by drawing lines in gaps in the data; the separating lines can be linear, quadratic, cubic, etc. depending on how specified. In this case, they are cubic functions Results of the SVM Classifier on our Training Data: |
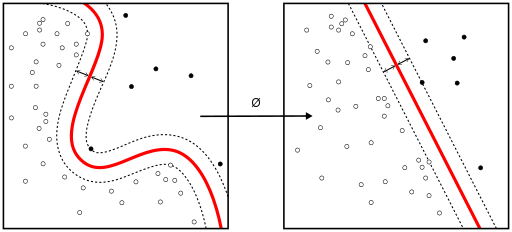
https://en.wikipedia.org/wiki/Support_vector_machine#/media/File:Kernel_Machine.svg
|
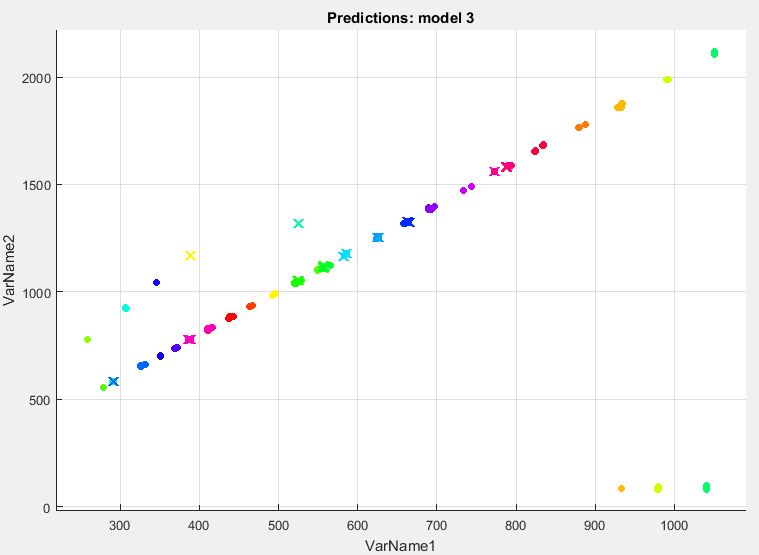
- Has a lower accuracy of 87.1%; We will not be using this type of classifier, but explored it as an option |
|
