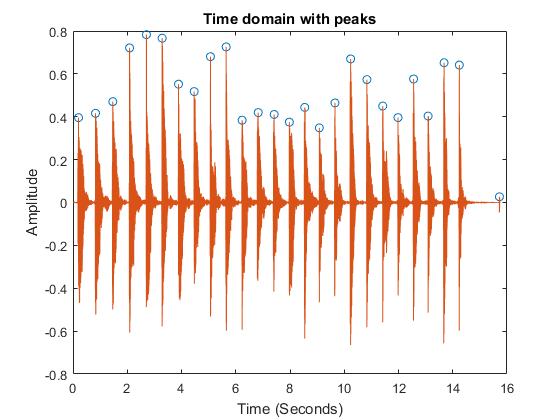
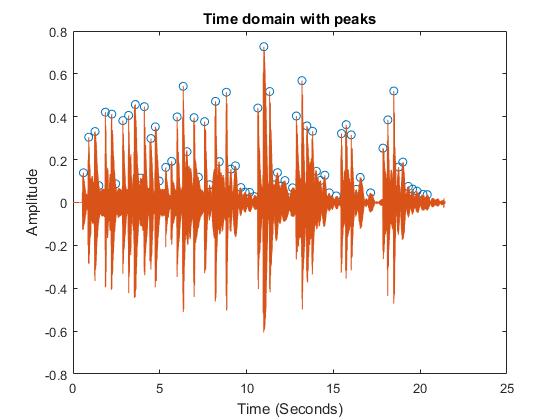
Segmentation
As the recording that we input to the algorithm is a continuous signal of notes, we need to split it into different time segments.
We wrote our own algorithm for this purpose, where we detected the peaks whose amplitude was larger than a threshold and whose prominence was greater than a selected value. This way, we got a as many vectors as the notes played in the recording and we could analyze them separately to detect the main frequency of each one and output the corresponding note.
The following images show the peak detection. Each segment is composed by the signal that goes from peak to peak.
We wrote our own algorithm for this purpose, where we detected the peaks whose amplitude was larger than a threshold and whose prominence was greater than a selected value. This way, we got a as many vectors as the notes played in the recording and we could analyze them separately to detect the main frequency of each one and output the corresponding note.
The following images show the peak detection. Each segment is composed by the signal that goes from peak to peak.